

Designing for Reliability (DFR) is an essential part of the product development process. A recall like the Samsung Note 7 can kill your company.
In B2B, the problem is not as public, and quantities are not as high.
But in a factory setting, malfunction of industrial equipment may bring down the line for days. Even if the device is not as mission-critical, you will still need to send a very pricey service engineer.
Besides the short-term financial pain, there is also the long-term damage to your brand.
While every electronic product, indeed, can be expected to degrade after some years in service, early failures are inadmissible and, most of the time, are the result of either an insufficiently tested design or poor manufacturing.
To reduce the chance of failure of your electronics, your team must design a healthy margin between stress and strength. If the stress endured by a product is more significant than its strength, it’ll fail.
Keep in mind that DFR has to occur early in the design stage when engineers begin to assess the feasibility of a concept, long before you start building prototypes.
Follow these five steps to make sure your electronic device is Designed For Reliability.
“As a rule of thumb, Designers should always consider reducing design complexity and maximizing the use of standard (proven) components”
1- DEFINE RELIABILITY REQUIREMENTS
First, you have to define the reliability requirements and objectives for the product, clearly and quantitatively, as well as the end-user environmental conditions during use and shipping.
For electronics, you must pay special attention to:
- Design Failure Mode and Effect Analysis (DFMEA)’ Design For Manufacturing (DFM)
- Supply Chain Set Up
Something which you must keep in mind at all times, in particular, is to make sure the client’s expectations on desired product lifetime and performance are clearly communicated.
Remember quality is conformance to specifications, if something is not specified you are not likely to get it. It is also important to make a difference between “absolutely needs to: use shall” and “would be nice to use should” requirements. Once you start testing prototypes the engineering team may realize that in reality some “shall” requirements may turn out be to a lot more costly to realize than initially expected, and may have to be softened to still be able to meet unit cost and Time To Market targets.
For all requirements, not just those on reliability, we strongly recommend building a Requirements Traceability Matrix (RTM) where for each Requirement a test has been defined. The logic then becomes: if it can’t be tested, it’s not a requirement.
HOW TO DEFINE RELIABILITY STANDARDS FOR ELECTRONICS?
There are a couple of ways to do this. The following list is meant to give you some ideas:
- Safety
- Contractual performance standards
- Expected Product Lifetime. This needs to be clearly defined. For example, a battery or lamp should not be expected to have a lifetime of X years, but rather X charges or X working hours at a certain intensity.
- Competitive Benchmarks, best practices, such
- Cost
Many industries have their own specific standards, for example:
- MIL-STD-810 – for military products (a.k.a. mil-spec). These tend to be much more demanding than for consumer items, i.e. display to withstand a 1 KG metal ball dropped on it from 1 meter height.
- IPC-SM-785 – Guidelines for Accelerated Reliability Testing of Surface Mount Solder Attachments
- Telcordia GR3108 – Generic Requirements for Network Equipment in the Outside Plant (OSP)
- IEC 60721-3 Stationary use at weather protected locations
If you are new to an industry, looking at the standards of the best competing products is a good start.
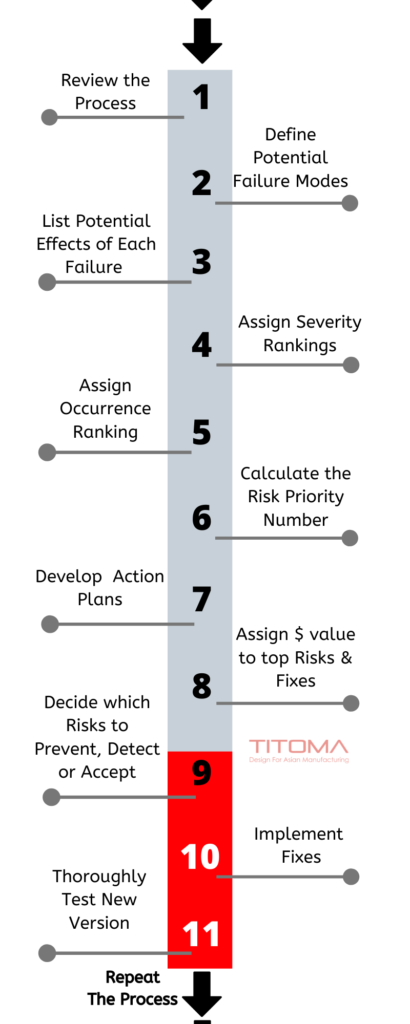
2- IDENTIFY KEY RELIABILITY RISKS
Now you should run DFMEA analysis to identify key reliability risks
DFMEA stands for Design Failure Mode and Effects Analysis, during this process, an experienced engineering team should review all components, assemblies, and subsystems to identify possible failure modes, their causes, and effects.
DFMEA will help you identify potential failure statuses for a product or process, evaluate the risks associated with these failure patterns, prioritize corrective actions, and identify and implement corrective actions to address the most acute concerns.
The DFMEA takes as inputs:
- Product requirements
- End-user usage
- Environment information
The purpose of the DFMEA is to take actions to eliminate or reduce failures, starting with the highest-priority ones based on the highest Risk Priority Number.
The kind of failures you might encounter of course really depend on your electronic device requirements and manufacturing set-up.
“Corrective action” is to fix a problem found. “Preventive action” is to implement a design change to make sure the problem does not arise again.
Depending on the kind of failure you identify, you can take preventive corrective actions, let’s take a look at some scenarios.
Fixing one problem may introduce a new problem or smaller problems that were hiding behind a big problem, for example first there is no wireless connection, when that connection is then established it turns out to have too much noise.
So every new version (of hardware AND firmware) needs to be thoroughly tested again.
Multiplying the chance of a failure happening (Occurrence) with the level of damage it would cause (Severity) gives you an RPN (Risk Priority Number) this allows you to rank, and identify the problems you need to tackle first.
Eliminating a failure mode can take substantial money and time, and the biggest problems should be assigned a dollar value (also consider the cost of liability and non-conformance) to make a cost-benefit analysis.
Case –TITOMA CEO: I have heard of quite a few cases where a Failure Mode was really hard to replicate, and in the end turned out to be a flaw in the IC or SOC, which the IC vendor typically refuses to admit. In those cases, you will need to have someone literally open up the IC to prove the vendor it has a fatal flaw.
It is important to realize that in practice you can never completely remove all risk of failure, as for most products Time To Market is really important.
Every month delay means a $ value of margin foregone. Miss your market window completely and the product will simply not sell, and all effort and investment to engineer the perfect product will have been in vain.
For some problems finding the root-cause, and the fix for it (Prevention) may take a very long time, so sometimes you –temporarily- have to resort to Detection by Quality Control (QC).
The economics of eliminating a failure mode also heavily depend on the quantities you are producing, in B2B quantities tend to be much lower, and especially if labor is affordable, detection (and repair) may make more sense.
Few people know that just like with software products, the job of improving an electronic product is an ongoing process: maintenance engineering.
In the B2B arena, individual end-customers account for a relatively large part of the business, and so nearly every production run is slightly different and better than the last one.
This means also that Version Control is essential to help you to track back where defects were likely introduced, and speed up the debugging process.
HOW FAST SHOULD WE LAUNCH OUR ELECTRONIC PRODUCT?
Reid Hoffman famously said: “If you are not embarrassed by the first version of your product, you’ve launched too late.”
This attitude may be the reason many hardware startups with a software background are pushing for very early release for mass manufacturing.
They forget that in electronic hardware the costs of fixing a problem are a LOT higher once it is sold. A recall can kill your company.
Start-ups don’t have much to lose, if a substantial risk materializes they simply fold, leaving their customers (and often their factories) with bad products.
Established firms will not only consider the purely financial consequences of a risk, but they also have to consider the impact on their brand equity, which can be hard to value.
Engineers nearly always strive for perfection. In the end, the CEO needs to make a Business Decision when a product is “good enough” to launch. That is a very tough decision, so it should be informed by a thorough FMEA analysis with solid data.
STEPS TO DESIGN FAILURE MODE AND EFFECTS ANALYSIS
3- DO A PHYSICS OF FAILURE ANALYSIS
This is one of the most critical aspects of Design for Reliability; reliability engineers can only make electronics reliable if they understand how they fail.
A Physics of Failure model focuses on the particular relationships between stresses and materials.
It begins with an understanding of materials, processes, physical interactions, degradation, and failure mechanisms, as well as identifying failure models.
Failure physics analysis proactively integrates reliability into the design process by creating a scientific basis for assessing new materials, structures, and technologies.
The modeling and simulation approach is used to qualify the design and manufacturing process, with the ultimate goal of eliminating failure early in the design process by addressing the root causes.
4- TEST AND IMPROVE PROTOTYPES
After both previous analyses have been done, in theory, your design should be optimized enough to be pretty reliable.
However, that’s the theory, now comes the reality of testing prototypes in the lab, and later pilot run units in the field, used by real target users.
Unless your team is really experienced in the project category, these tests will bring up failure modes no one ever thought about.
Skimp on testing at your peril, the further in the design to manufacturing process you discover a problem, the more expensive it is to fix it. Tweaking a prototype versus the very costly processing of RMA’s (products returned because they failed)

Adapted From: “Design for Manufacturability” by David M Anderson 2001
Less experienced engineers tend to dismiss prototype failures as being caused by the less than perfect prototyping processes.
In many cases this is true, but every failure observed in a prototype should be logged and considered a potential failure mode to be further analyzed.
Thorough tests with prototypes can contribute to confidence or lack of confidence in the design approach, and this is always valuable input for building the next prototype and ultimately manufacturing the final product.
The product test scenarios should be done considering the product environment, duty cycles, and performance requirements as defined in the Product Requirements Document.
Before starting the prototyping test, make sure you understand whether they are all from the same configurations or whether they contain different subcomponents or aggregation methods that may affect the statistics from the reliability test.
Make sure you understand the root cause of all perceived failures and design an action plan to correct them.
It is very important to realize that design changes at this point are easier and far less costly to implement than in subsequent stages of product development and manufacturing.
IMPLEMENT HIGHLY ACCELERATED TESTS (HALT/HASS)
HALT’s objective is to proactively help you find and fix vulnerabilities, thereby increasing your product’s reliability.
- Temperature
- Vibration
- Humidity
- Voltage
- Current
- Power cycling
The product being tested will be running during the HALT test and should be monitored continuously to check for malfunctions.
When stress-related failures occur, the cause must be identified, and if possible, the problem should be fixed so that the test continues to find other weaknesses.
Because of its accelerating nature, HALT is usually faster and less expensive than other testing techniques.
Here again, there is a commercial trade-off between the level of comfort your brand reputation requires and the time and money you are able to spend on these tests.
5- VALIDATE, MONITOR, AND CONTROL
All the analysis and testing we just talked about should be done continuously until your electronic device design is considered to be acceptable for mass manufacturing.
When you finally reach the manufacturing stage, all the efforts of your reliability engineering team should be focused on reducing or eliminating any adverse effect the manufacturing process might cause on the final product.
The manufacturing process adds variables such as human operators, human errors, factory contamination.
This is why DFR is not enough to make sure your electronic device will be a manufacturing success; DFM (Design For Manufacturing) is also something you and your team should keep in mind from the very beginning.
Please don’t think that the DFR process ends when your electronic device is delivered to your client.
Constant monitoring and analysis of field data are necessary to monitor product behavior in actual use and misuse conditions.
Your team should use this knowledge to continuously further improve the device in the next manufacturing runs. This effort called sustaining engineering is really important, to successively drive out as many failure modes as possible.
Of course, the information gained in field tests and RMA root-cause analysis is also very valuable to inform future related product development projects.
Post-Mortems are really important for continuously improve, review both success and mistakes, and ensure that the lessons learned in this process are not lost.
One final piece of advice, when it comes to components selection, some might tell you that as long as you stick to a trustworthy supplier, you’ll be good to go, but this isn’t always the case.
Even the best of suppliers can have quality issues, which is why validating components regardless of suppliers is a much safer approach.
DESIGN FOR RELIABILITY OF ELECTRONICS – CONCLUSION
Just like DFM, Designing For Reliability is not a sauce you add at the last moment, just before the beginning of product manufacturing.
Instead, it is a process closely intertwined with the rest of the stages of product development as different factors such as electric components selections and manufacturing processes could harm your electronics’ reliability if not done correctly.
In today’s world, where:
- fast-moving technologies push you to work with relatively unproven solutions, ;
- more competition and shorter component life cycles push you for faster time to market
- increased emphasis on cost reduction
A strong emphasis on Design for Reliability is the only way to build and maintain your reputation.

FAQ – DESIGN FOR RELIABILITY
Design for Reliability (DFR) is a process that includes tools and procedures to ensure that the product meets its reliability requirements, in its own environment of use, throughout its life span. DFR is implemented at the product design stage to proactively improve product reliability. DFR is often used as part of a comprehensive design strategy for excellence (DFX).
DFR stands for Design for Reliability
Reliability is quantified as MTBF (Mean Time Between Failures) for repairable product and MTTF (Mean Time To Failure) for the non-repairable product.
MTBF= T/R where T = total time and R = number of failures
MTTF= T/N where T = total time and N = Number of units under test.
If the MTBF is known, one can calculate the failure rate as the inverse of the MTBF. The formula for failure rate is failure rate= 1/MTBF = R/T where R is the number of failures, and T is total time.
To improve product reliability, failure data and information is collected during a certain period, then analyzed and corrective actions are taken. The reliability measure depends on the type of products.
Test-retest Reliability.
Interrater Reliability.
Parallel forms reliability.
Internal consistency.
The reliability of an electronic device is extremely design-sensitive.
Tiny changes to the design of a component can cause profound changes in reliability, which is why it is essential to specify product reliability and maintainability targets before any design work is undertaken.
The last thing you want is a massive RMA situation like the one SAMSUNG had when its cellphones were exploding.
